Uniform Tool Use
Existing agents often apply fixed tool workflows across different spatial tasks, causing mismatched evidence and limited gains.
Agentic 3D Spatial Reasoning
Query type · target objects · required evidence
Rollouts · tool outputs · success / failure traces
Workflows + failure lessons
Agentic SFT + GRPO
Motivation

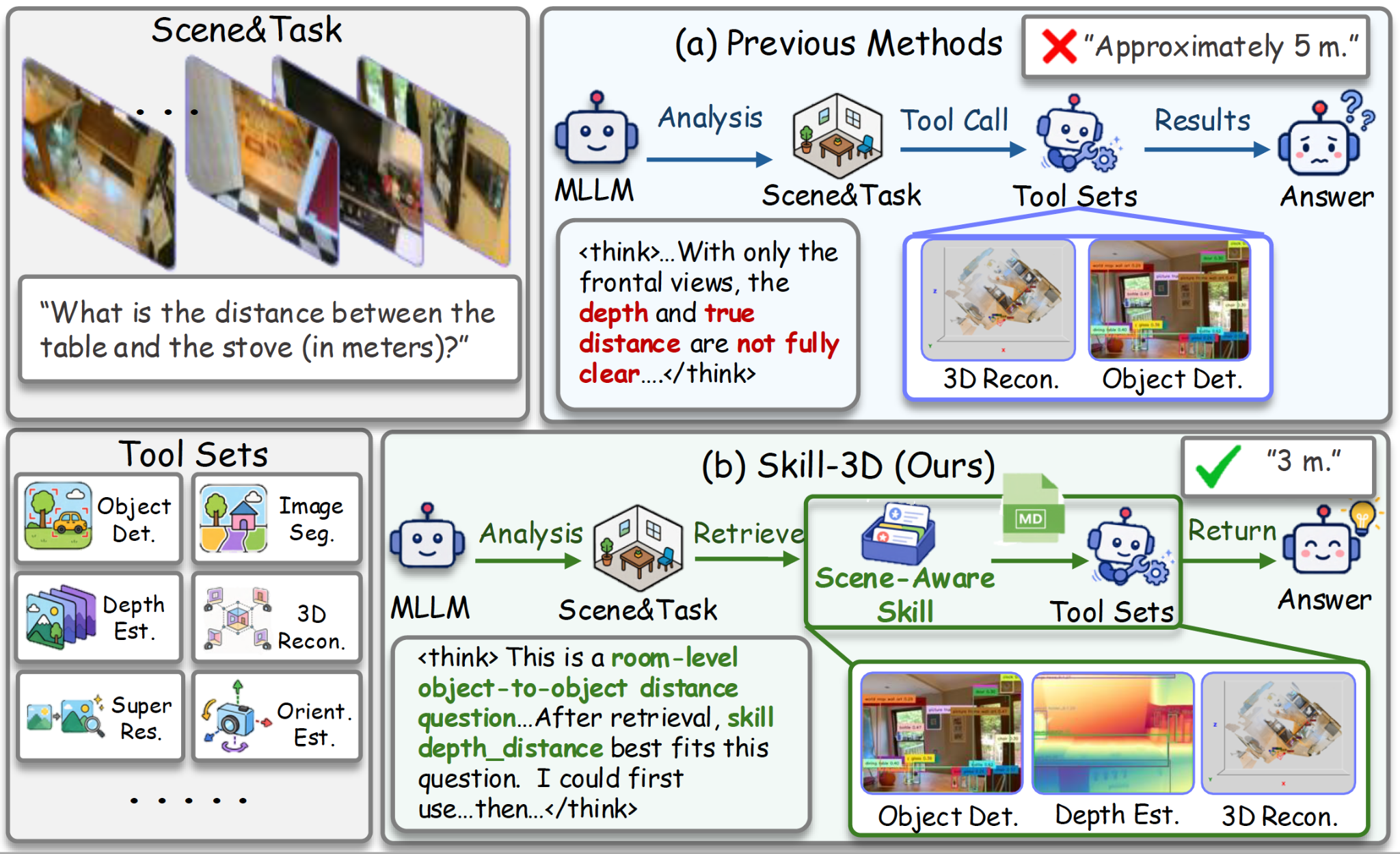
Existing agents often apply fixed tool workflows across different spatial tasks, causing mismatched evidence and limited gains.
Skill-3D retrieves task-specific skills to select the right tools and ground answers in relevant 3D evidence.
Method
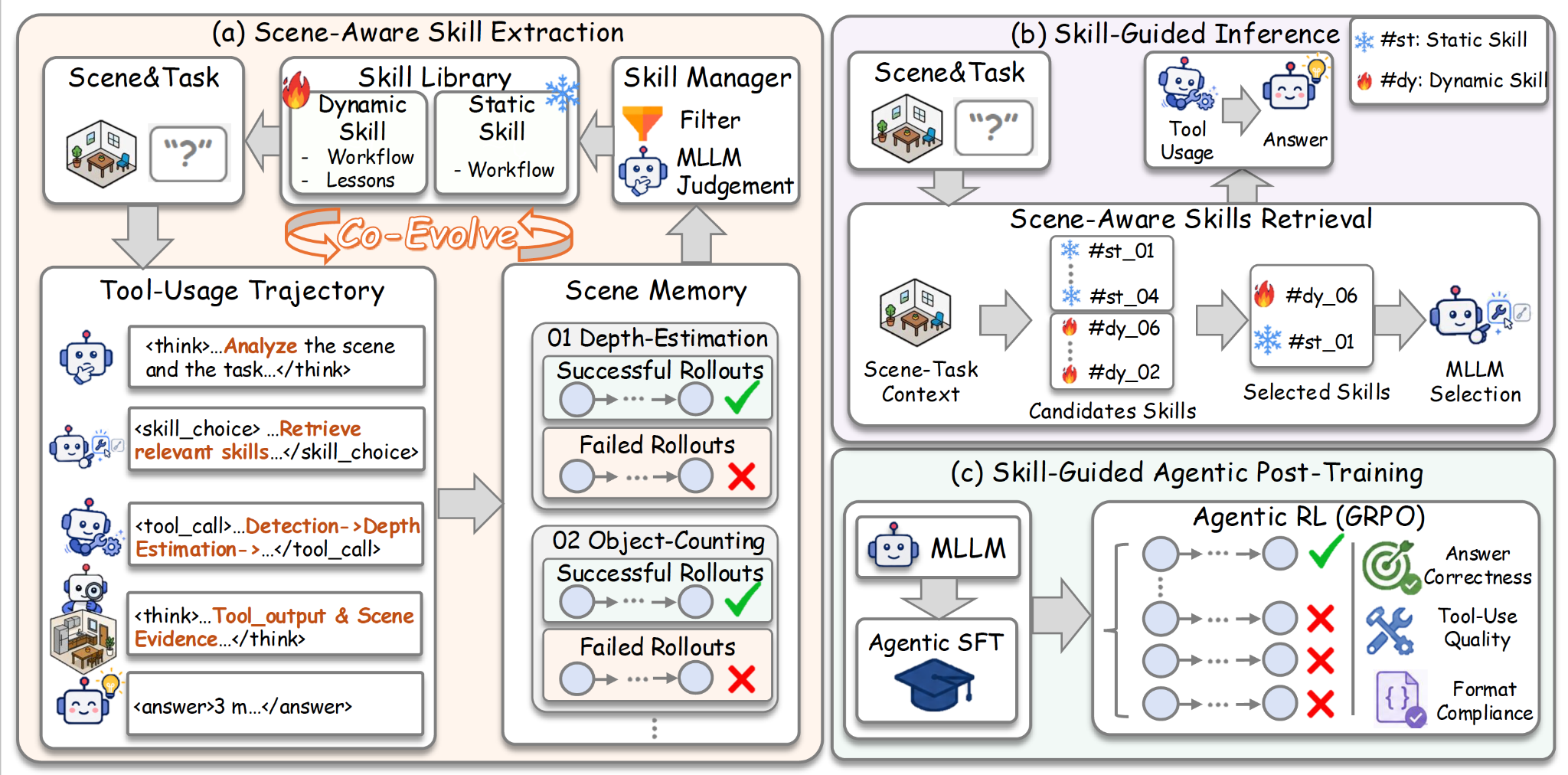
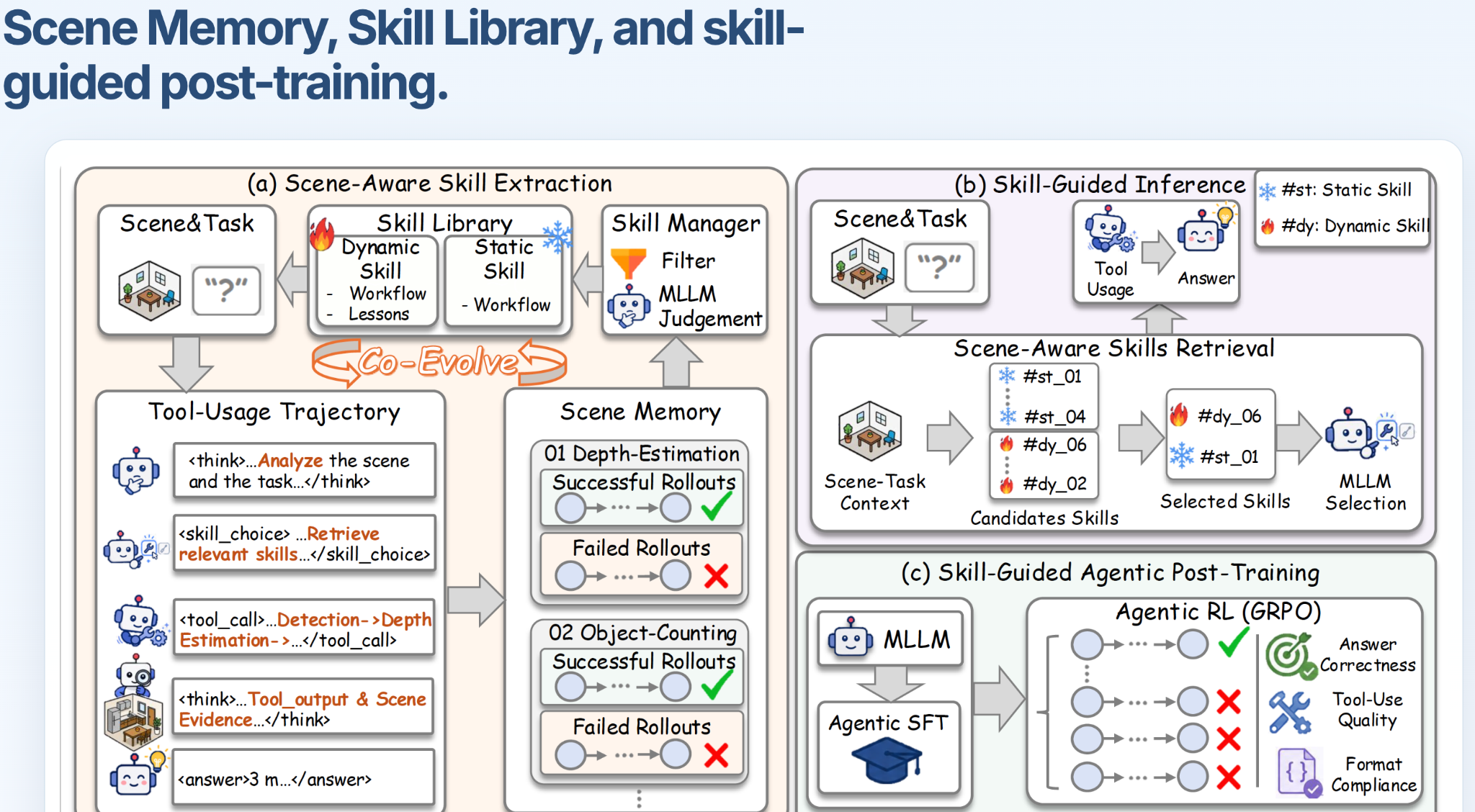
Successful rollouts become reusable workflows; failures become lessons.
Skill-3D retrieves relevant skills and uses a compact subset to guide tool use and reasoning.
Skill-guided trajectories train compact agents to select skills, call tools, and ground answers through SFT and GRPO.
Results
VSI-Bench, BLINK, CV-3D, and MMSI-Bench

Closed-source evaluation across GPT-4o, GPT-5.4, Gemini-2.5-Pro, and Gemini-3-Flash.
Skill-3D consistently outperforms non-agentic, direct tool-use, and Think3D baselines across four closed-source MLLM agents. The gains are most pronounced on VSI-Bench, where different spatial categories require task-specific evidence such as object grounding, depth estimation, and multi-view verification.
Skill-guided post-training transfers to compact Qwen3-VL-4B/8B agents. The results show that scene-aware tool-use behavior can be internalized by smaller policies through agentic SFT and GRPO, improving skill selection, tool usage, and evidence-grounded answering.
Analysis
Hover over each bar to inspect the exact value.
Bars show tool-call frequency by task group; hover for exact values.
Qualitative Cases
Citation
@article{skill3d2026,
title = {Skill-3D: Evolving Scene-Aware Skills for Agentic 3D Spatial Reasoning},
author = {Haoyuan Li and Zhengdong Hu and Jun Wang and Hehe Fan and Yi Yang},
booktitle = {arxiv preprint arxiv:2606.07436},
year = {2026}
}